

Demo: Use SEA to review the paper.
In recent years, the rapid increase in scientific papers has overwhelmed traditional review mechanisms, resulting in varying quality of publications. Although existing methods have explored the capabilities of Large Language Models (LLMs) for automated scientific reviewing, their generated contents are often generic or partial. To address the issues above, we introduce an automated paper reviewing framework SEA. It comprises of three modules: Standardization, Evaluation, and Analysis, which are represented by models SEA-S, SEA-E, and SEA-A, respectively. Initially, SEA-S distills data standardization capabilities of GPT-4 for integrating multiple reviews for a paper. Then, SEA-E utilizes standardized data for fine-tuning, enabling it to generate constructive reviews. Finally, SEA-A introduces a new evaluation metric called mismatch score to assess the consistency between paper contents and reviews. Moreover, we design a self-correction strategy to enhance the consistency. Extensive experimental results on datasets collected from eight venues show that SEA can generate valuable insights for authors to improve their papers.
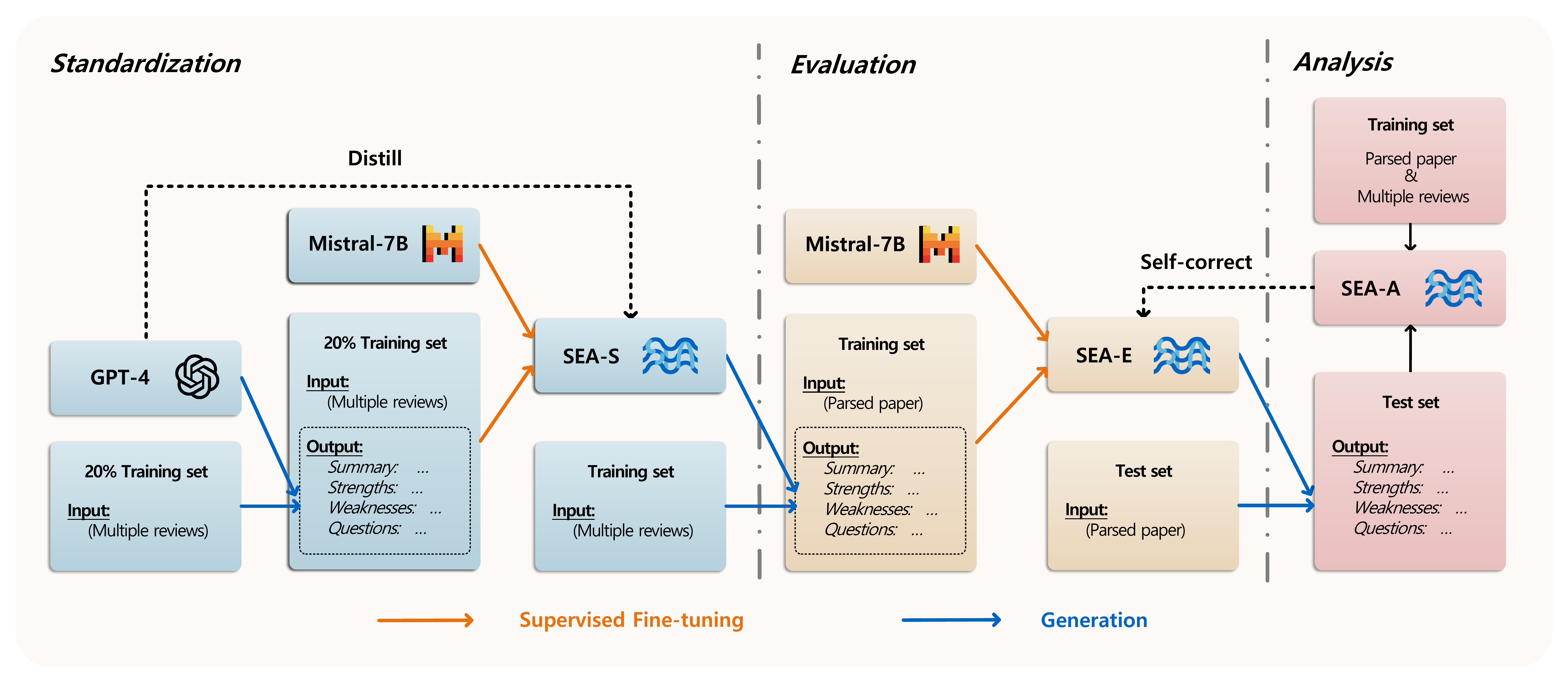
The overall framework of SEA consists of three modules, Standardization, Evaluation and Analysis.
In the Standardization module, we develop a model SEA-S, which aims to integrate all reviews for each paper into one to eliminate redundancy and errors, focusing on the major advantages and disadvantages of the paper. Specifically, we first utilize GPT-4 to integrate multiple reviews of a paper into one that is in a unified format and criterion with constructive contents, and form an instruction dataset for SFT. After that, we fine-tune an open-source Mistral-7B to distill the knowledge of GPT-4. Therefore, SEA-S provides a novel paradigm for integrating peer review data in an unified format across various conferences.
In the Evaluation module, our objective is to develop a proficient LLM that can comprehend academic papers and produce constructive reviews. Since the papers are in PDF format, we utilize Nougat to parse them into text and LaTeX codes. To handle the long-text nature of these papers, we use the open-source model Mistral-7B as the backbone, known for its effectiveness in managing up to 16K tokens in the long-context benchmark RULER. The parsed papers, standardized reviews from SEA-S, and human-crafted prompts form an instruction dataset. This dataset enables SEA-E to generate comprehensive and constructive reviews following SFT.
In the Analysis module, we introduce a mismatch score to measure the consistency between academic papers and their generated reviews. A high mismatch score indicates lower review quality, while a score of zero suggests a neutral, consistent review. To estimate mismatch scores, we train a regression model named SEA-A. After training SEA-A, we implement a self-correction strategy. If the estimated mismatch score exceeds a threshold, the review is regenerated with the mismatch score as an additional prompt to enhance consistency.
We conduct evaluations on four cross-domain datasets: CONLL-16, ACL-17, COLING-20, ARR-22, and four in-domain datasets: NeurIPS-16-22, ICLR-17-22, NeurlPS-23, ICLR-24. In our framework, there are two methods for generating reviews: SEA-E and SEA-EA, where SEA-EA is an enhanced model that combines the Analysis module with SEA-E.
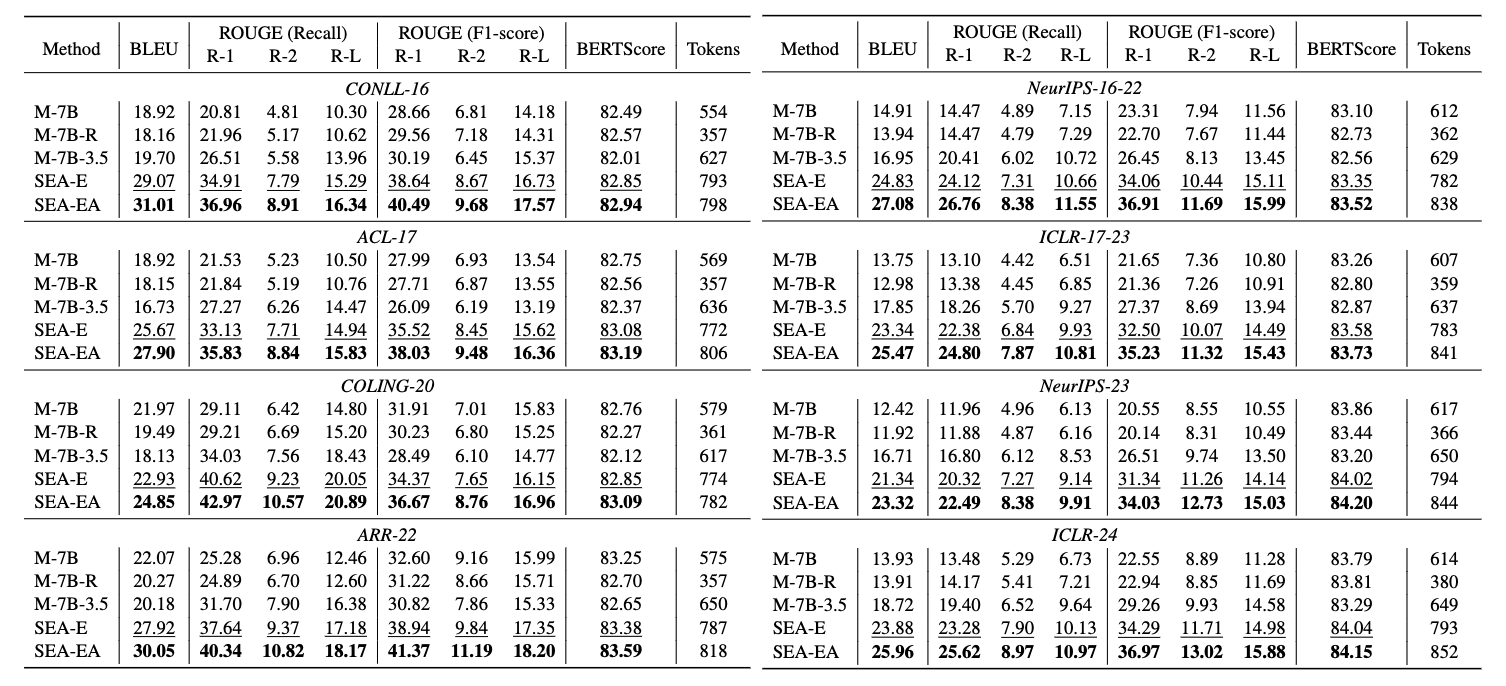
Results. The results show that SEA outperforms other baseline models across all the testing scenarios, with particularly notable gains on the ROUGE (Recall) metric. This confirms that our proposed framework SEA is capable of generating comprehensive and constructive reviews. Further, SEA not only performs excellently on in-domain tasks but also shows strong performance on cross-domain datasets, demonstrating its robust generalizability. It is also worth noting that SEA-EA surpasses SEA-E in all cases, underscoring the effectiveness of the self-correction strategy in generating well-grounded reviews consistent with raw papers.
We present standardized results from the training sets of NeurIPS-2023 and ICLR-2024, which have different rating criteria and various formats for organizing reviews.
We compare SEA-S with Mistral-7B, GPT-3.5, and GPT-4 to evaluate their review standardization performance. All the models are fed with the same inputs. Since there is no ground-truth text for this standardized task, we utilize reviews generated by SEA-S as references, while reviews generated by other models serve as candidates. Next, we calculate recall and precision values of ROUGE for candidates compared to references. Based on the content intersection of reference and candidate, recall and precision refer to the percentage of intersection in reference and candidate, respectively. From the two metrics, we can deduce the percentages of overlapping and exclusive semantic information in both reviews, whose results are shown below. We compare the model performance w.r.t. different ROUGE metrics, including ROUGE-1 (R1), ROUGE-2 (R2), and ROUGE-L (RL). The light blue area in the figure indicates the overlapping contents, while the dark blue and light grey areas represent the exclusive contents by SEA-S (reference) and other models (candidate), respectively.
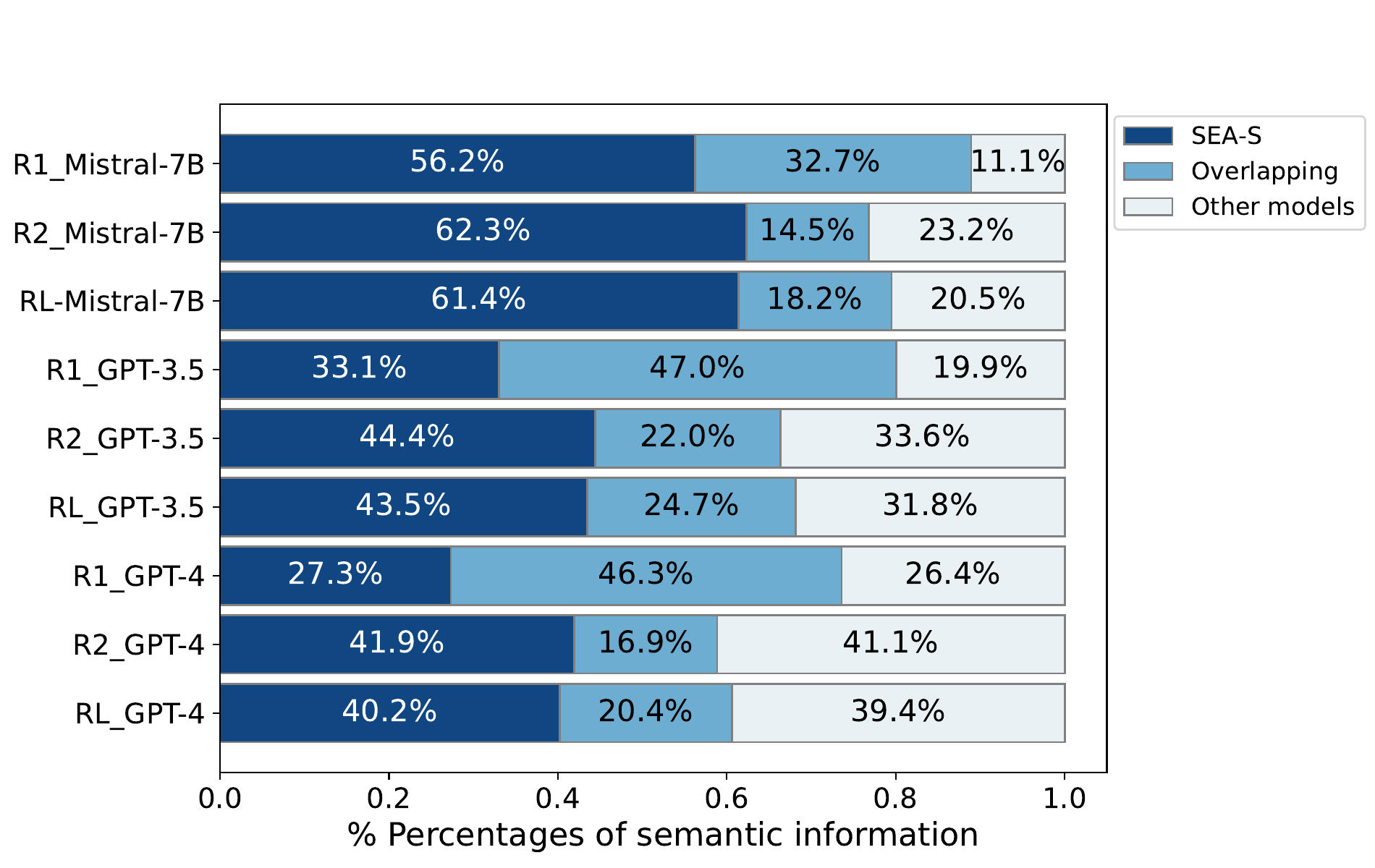
Results. From the figure, we see that, SEA-S can generate a significantly larger percentage of exclusive contents than both Mistral-7B and GPT-3.5. This further verifies that SEA-S can better standardize reviews with richer information.
Standardized data formats can help LLMs better understand the correspondence between the instruction and generated content during SFT. To perform format analysis, we utilize regular expression matching based on instruction formats to calculate the proportion of correctly formatted reviews integrated by different models.
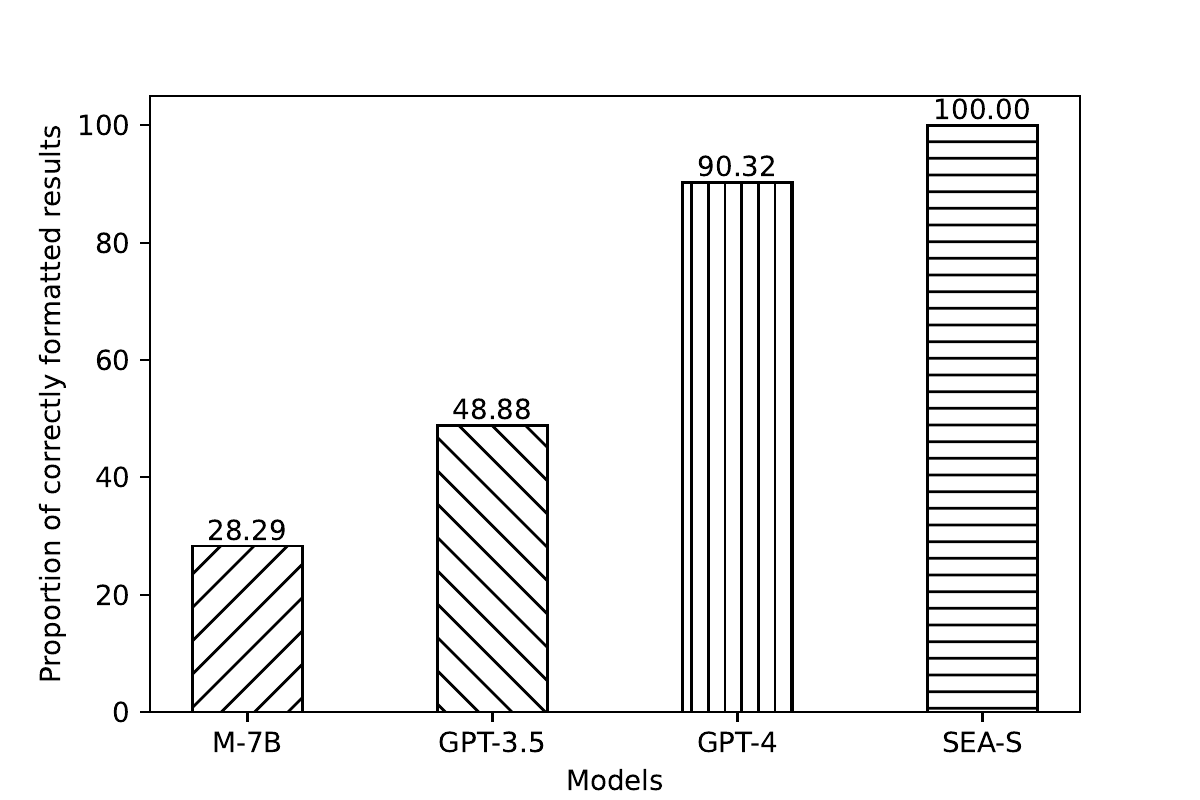
Results. The results demonstrate that SEA-S is capable of generating 100% correctly formatted data. Also, we observe that around 10% of the data integrated by GPT-4 does not fully comply with the instruction. Overall, SEA-S demonstrates excellent effectiveness in handling reviews of various formats and criteria.
To analyse the consistency between the reviews generated by different models and the corresponding papers, we input the reviews and their respective papers in the test set into the trained SEA-A model to calculate the average mismatch score for each model across different datasets.
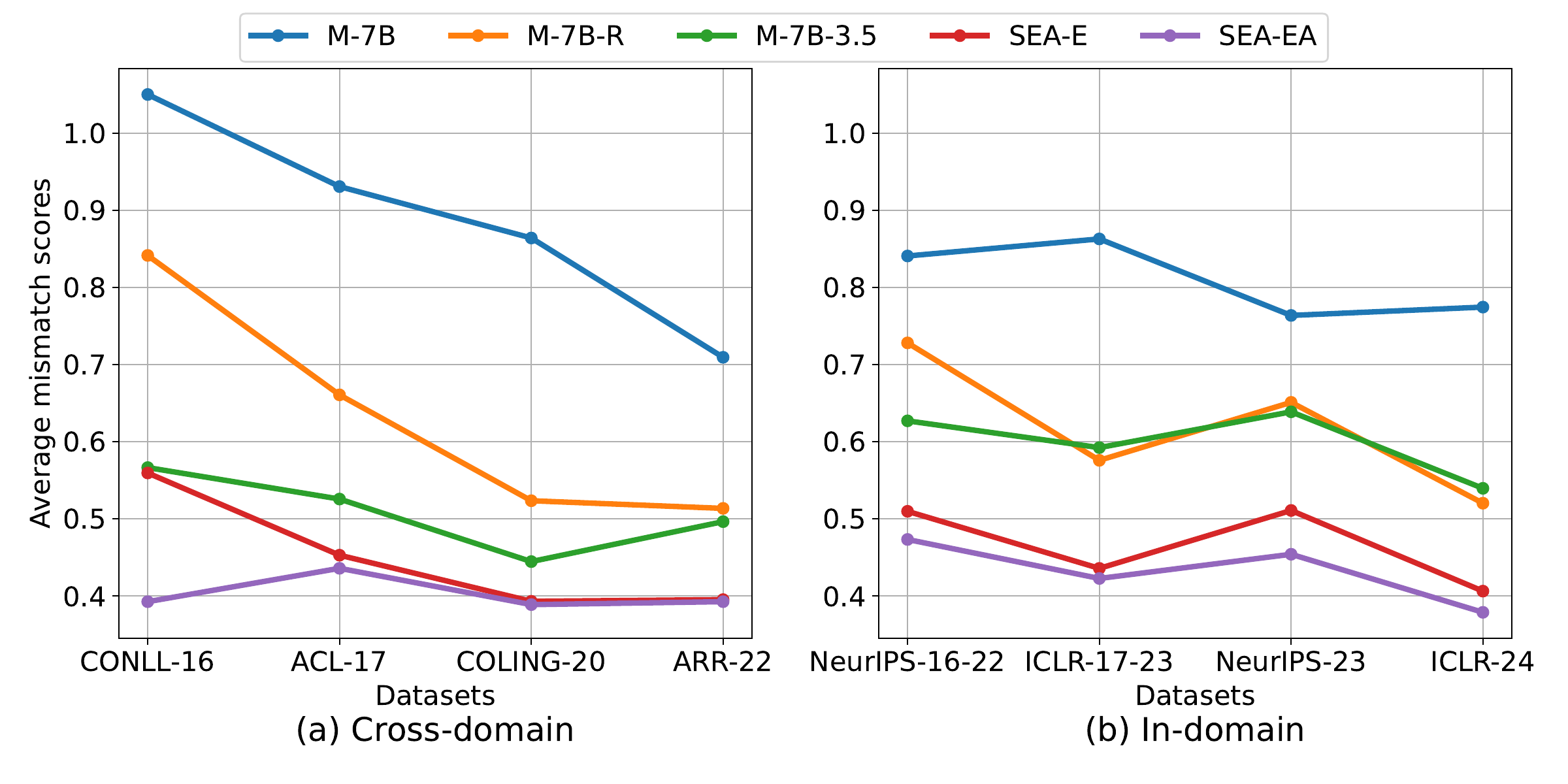
Results. SEA-EA, due to its self-correction strategy, consistently outperforms others across all the datasets. Further, SEA-E is the runner-up method. This verifies that the reviews generated by both methods have a higher consistency with their corresponding papers.
To conclude, it must be underscored that the primary objective of this paper is to provide informative reviews for authors to furnish authors with insightful critiques aimed at refining their works, rather than directly influencing decisions regarding the acceptance or rejection of the papers. We have also emphasized this point in the supplementary clauses of the model's license.
@inproceedings{yu2024automated,
title={Automated Peer Reviewing in Paper SEA: Standardization, Evaluation, and Analysis},
author={Yu, Jianxiang and Ding, Zichen and Tan, Jiaqi and Luo, Kangyang and Weng, Zhenmin and Gong, Chenghua and Zeng, Long and Cui, RenJing and Han, Chengcheng and Sun, Qiushi and others},
booktitle={Findings of the Association for Computational Linguistics: EMNLP 2024},
pages={10164--10184},
year={2024}
}